
Reference Tables
Introduction
Reference Tables are managed as simple configuration element in the IDC, either through import/export of CSV files or through standard configuration XML import/export. Their purpose is to be used inside business rules, which is possible through an API made available to those rules. This page explains how to access and use this API.
General Overview
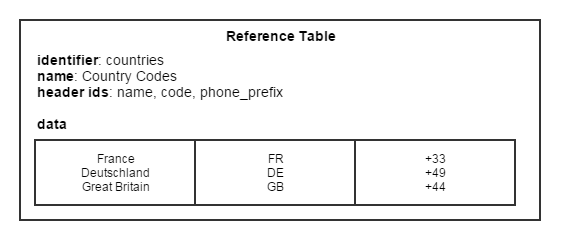
Reference Tables are characterized by:
An identifier
A list of headers, identified with an "header id"
A table of values, generally called the "data" of the table
A table's data is accessed either by index (third column of the second row) or by name, using the header id ('percentage' value of the second row).
API
A Reference Table Data is exposed through a ReferenceTableDataFinder object that provides a set of methods that let one query the data in meaningful ways. This object provides a classical Java interface but is also specifically designed to provide quick and fast access through Groovy scripts. Complete Reference Table data Rows are exposed through a ReferenceTableDataRow object.
ReferenceTableDataFinder
public interface ReferenceTableDataFinder {
/**
* Return the first row whose value for column named <code>headerId</code> is equal to the given <code>value</code> (ignoring case).
*/
ReferenceTableDataRow get(String headerId, String value);
/**
* Return the first row whose value for column at index <code>columnIndex</code> is equal to the given <code>value</code> (ignoring case).
*/
ReferenceTableDataRow get(int columnIndex, String value);
/**
* Return the first row whose value for the first column is equal to the given <code>value</code> (ignoring case).
*/
ReferenceTableDataRow get(String value);
/**
* Get the value for the second column in the line where the first column value is equal to the given <code>value</code> (ignoring case). This
* is useful when the data is considered a simple map of string key/value, to fetch the corresponding value for a given
* key.
*/
String valueOf(String value);
/**
* Returns all of the rows of the table, in order.
*/
List<ReferenceTableDataRow> findAll();
/**
* Returns all of the first <code>limit</code> rows, in order.
*/
List<ReferenceTableDataRow> findAll(int limit);
/**
* Returns all of the rows whose value for column named <code>headerId</code> contains the given <code>filter</code>
* (ignoring case), in order.
*/
List<ReferenceTableDataRow> findMatching(String headerId, String filter);
/**
* Returns all of the rows whose value for column at index <code>columnIndex</code> contains the given
* <code>filter</code> (ignoring case), in order.
*/
List<ReferenceTableDataRow> findMatching(int columnIndex, String filter);
/**
* List all values for the column named <code>headerId</code>, in order.
*/
List<String> list(String headerId);
/**
* List all values for the column at index <code>columnIndex</code>, in order.
*/
List<String> list(int columnIndex);
/**
* List all values of the first column. Useful for reference tables with a single column.
*/
List<String> list();
}ReferenceTableDataRow
public interface ReferenceTableDataRow {
/**
* Return the value of the first column.
* @return the first column value, maybe <code>null</code>
*/
String getFirst();
/**
* Return the value of the column at the given <code>columnIndex</code> index. This method is safe
* should the index be out of bounds (will return <code>null</code>).
*
* @param columnIndex the column index
* @return the value, <code>null</code> if there is none
*/
String getValue(int columnIndex);
/**
* Return the value of the column with the given <code>headerId</code> header identifier.
*
* @param headerId the header identifier
* @return the value, <code>null</code> if none found or if the header id is unknown
*/
String getValue(String headerId);
/**
* Return the row's values as a Map, indexed by header identifier.
*/
Map<String, String> getData();
/**
* Return the row's values as a List.
*/
List<String> getValues();
}Groovy Usage
Using the Finder methods
In Groovy the finder methods can be used directly, "as is":
myFinder.get("name", "France")
myFinder.list("code")Accessing Data
Data can be accessed either using the ReferenceTableDataRow methods, such as getValue(int) or getData(), but also using Groovy syntax sugar for properties and array index:
myFinder.get("name", "France")[0] // Access to the value for the first column (index 0)
myFinder.get("name", "France")['phone_prefix'] // Access to the value for the 'phone_prefix' column
myFinder.get("name", "France").phone_prefix // Access to the value for the 'phone_prefix' column, using property accessUsage in Script Rules
In Script rules, a Reference Table finder is accessed using the REF binding variable. One access a Reference Table using its id. Also, one can make use of the safe navigation operator to quickly access data:
REF['countries']?.get("name", "France")[0] // Access to the value for the first column (index 0)
REF['countries']?.get("name", "France")['phone_prefix'] // Access to the value for the 'phone_prefix' column
REF['countries']?.get("name", "France")?.phone_prefix // Access to the value for the 'phone_prefix' column, using property accessExamples
REF['countries'].findAll()[0][2] // Access the third value (index 2) of the first row of the 'countries' reference table
REF['countries'].findMatching("phone_prefix", "+3")[0] // Access to the the value of the first column of the first row where the prefix code contains "+3"
REF['countries'].valueOf("France") // Access to the value for the second column where the first column value is "France" (will return "FR")