
General Synchronization Principles
In this documentation part, we will present the general Synchronization service principles. Understanding them helps figure out the configuration logic, i.e. which elements are configurable and in which order.
Depending on the synchronization action that is set up, some concepts may be used and others not.
Overview
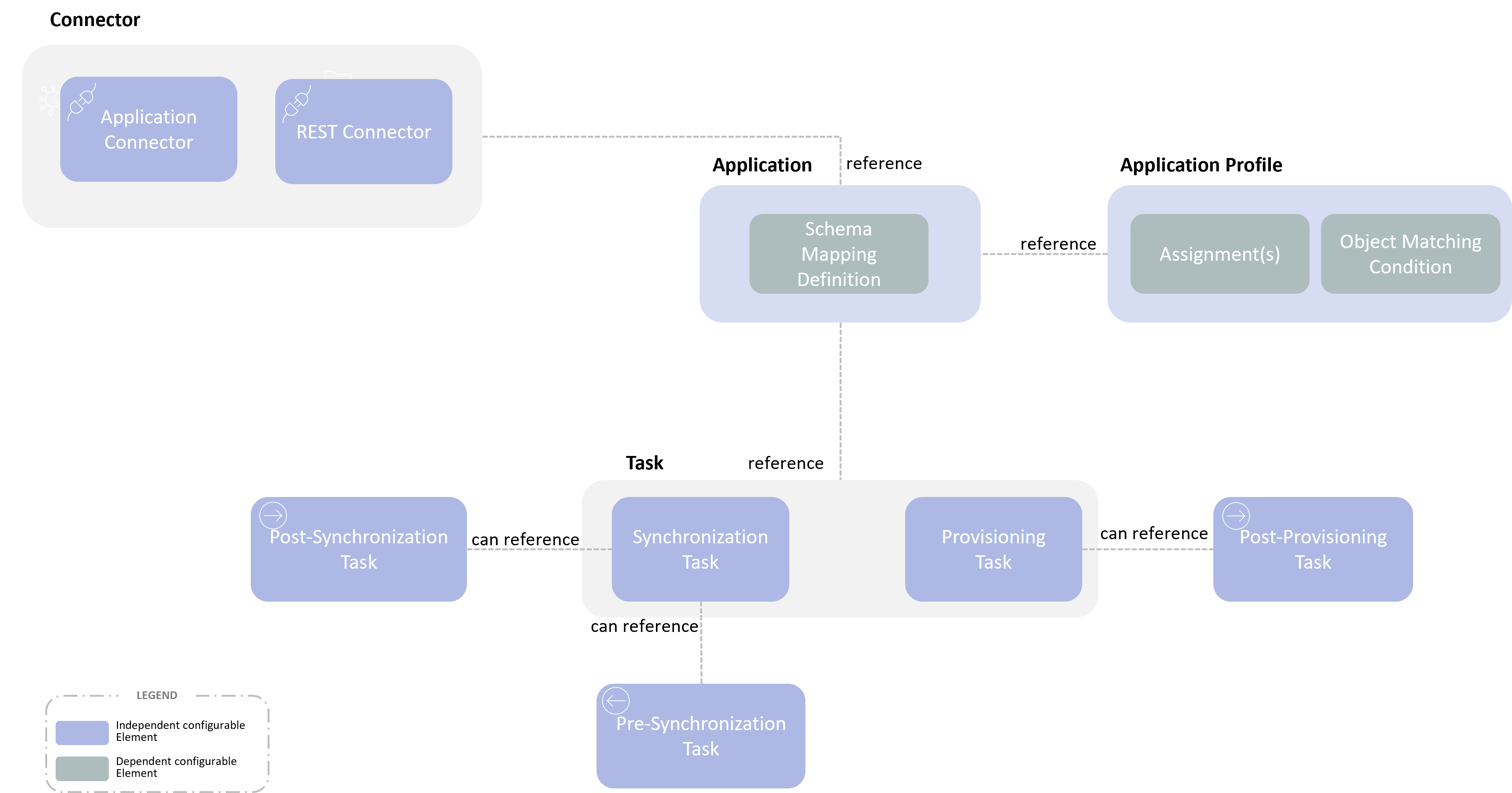
Synchronization service is composed of the following elements :
Connector: the technical settings enabling to communicate with a remote application, such as a LDAP directory
Application: the main synchronization configuration entry point, and by far the most complex. An "Application" conceptually designates a remote service, external to Synchronization service, exposing a repository of accounts (or organizations), such as a LDAP directory, or a CSV file. An Application's population may be divided into several IDM Object Types, hence the diversification, within an Application's configuration, of sub-configurations per Object Type
Synchronization Task : settings used to launch synchronization operations, namely by specifying the desired type of synchronization (among "reconciliation", "import", etc.), and the target Application
Synchronization Task Post Processing: settings used to launch the post processing task
Provisioning Task: settings used to launch provisioning operations
Provisioning Task Post Processing: settings used to launch the post processing task
Connector Definition
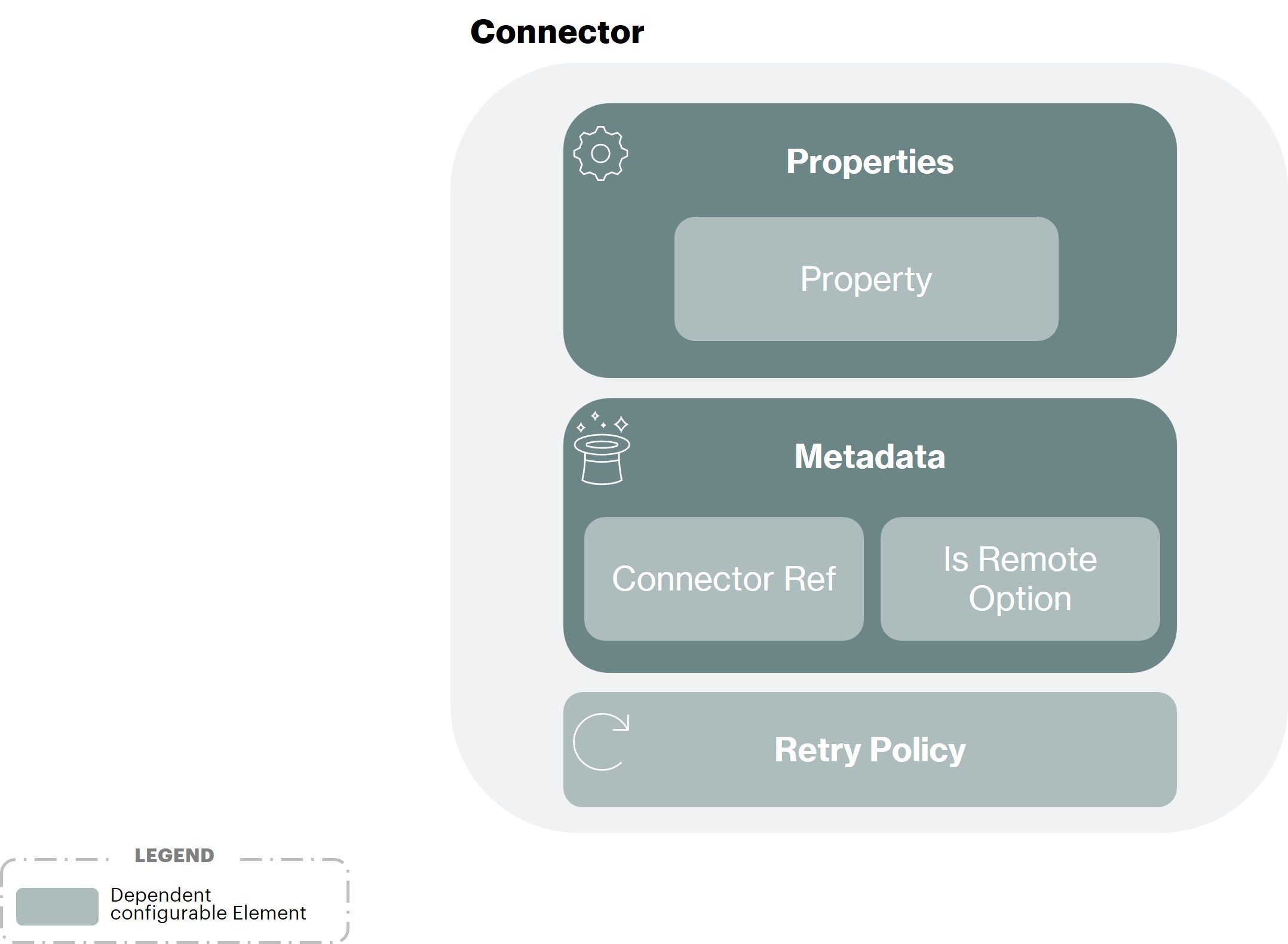
An Application Connector holds the technical configuration required to access a remote application, such as a LDAP directory. A CSV file also falls into the "remote application" category.
Interacting with Remote Applications
Synchronization service is using the ConnId Framework to interact with remote applications, such as a LDAP directory. ConnId is a continuation of the Identity Connectors Framework (ICF) created by Sun Microsystems. The term Connector will thus be used in the rest of this document to designate the component enabling Synchronization service to communicate with remote applications.
There is no need to install Connector components on remote applications; Connectors are fully part of the Synchronization service.
The configuration of a Connector is represented by a Connector Definition. It is mostly technical, it references IP addresses, ports, connection pool settings, etc. For the CSV Connector, the most significant configuration property is the CSV file location on disk.
The following diagram illustrates those principles:
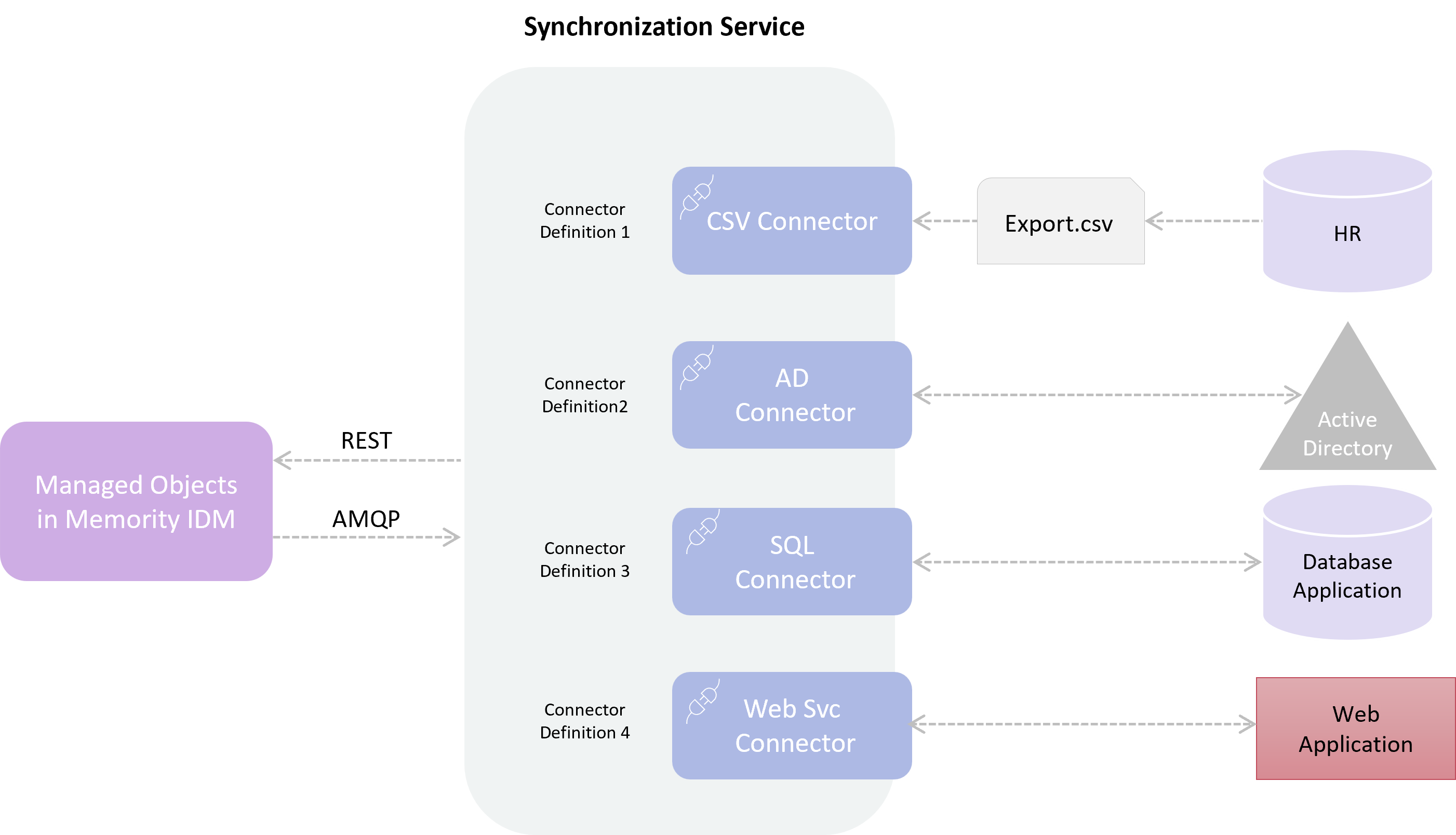
Interacting with the Memority IDM Service
Synchronization service interacts with the Memority IDM service in both ways:
from Synchronization service to Memority IDM service : via the Bulk REST API to send to the IDM create/update/delete requests in batch mode
from Memority IDM service to Synchronization service: via the AMQP Broker to receive from the IDM create/update/delete messages and react to them (not implemented yet)
Application
Application defines an entire synchronization configuration, which is roughly composed of:
a reference to a Connector Definition
Synchronization Definition: the actions to perform regarding the possible synchronization situations
Schema Mapping Definition: inbound/outbound attribute mapping rules
The overall configuration hierarchy of an Application is represented below.
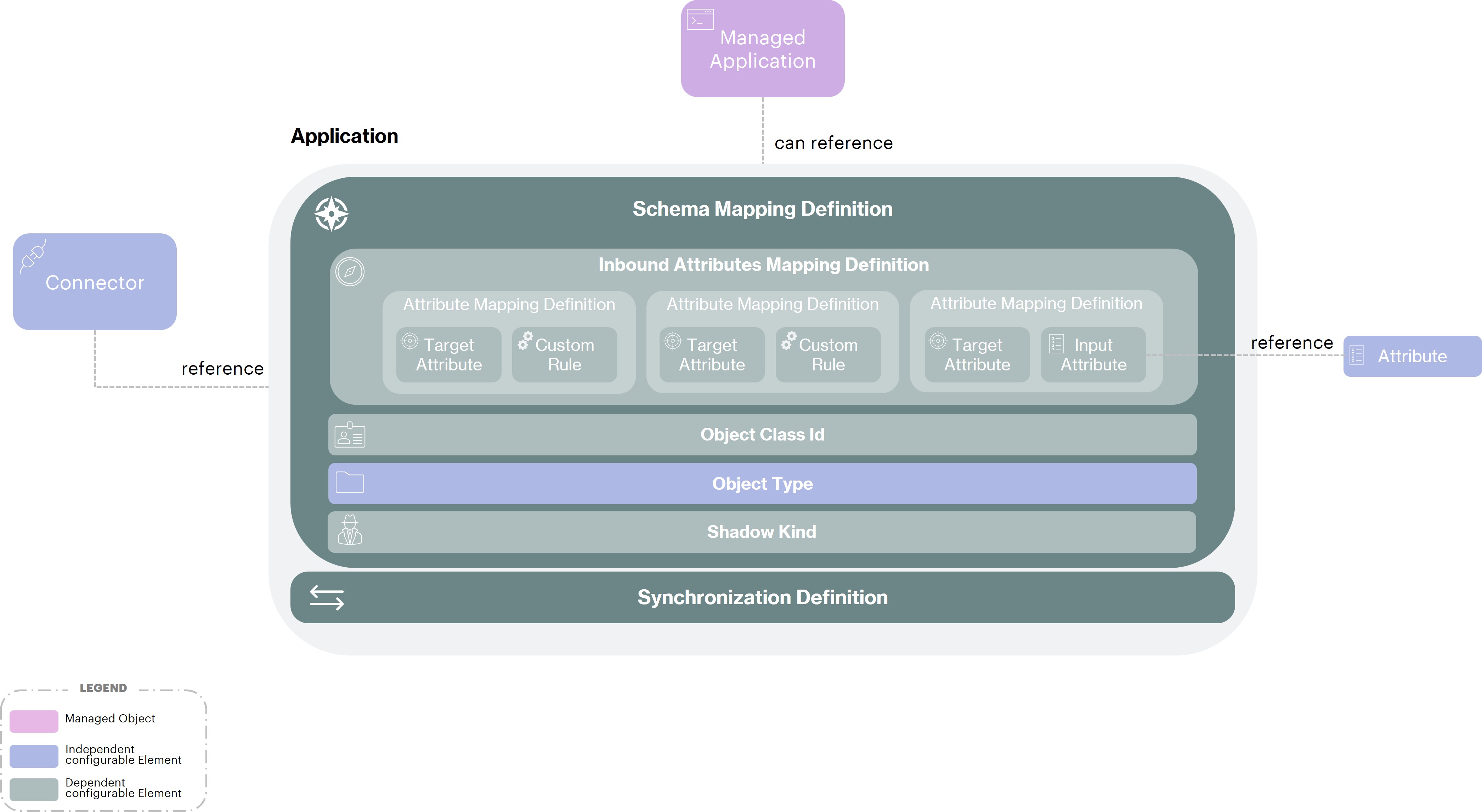
In the above schema, we have represented only one Schema Mapping Definition but there could be several, 1 dedicated per identity type. For example, a configuration for "employee", and another for "partner".
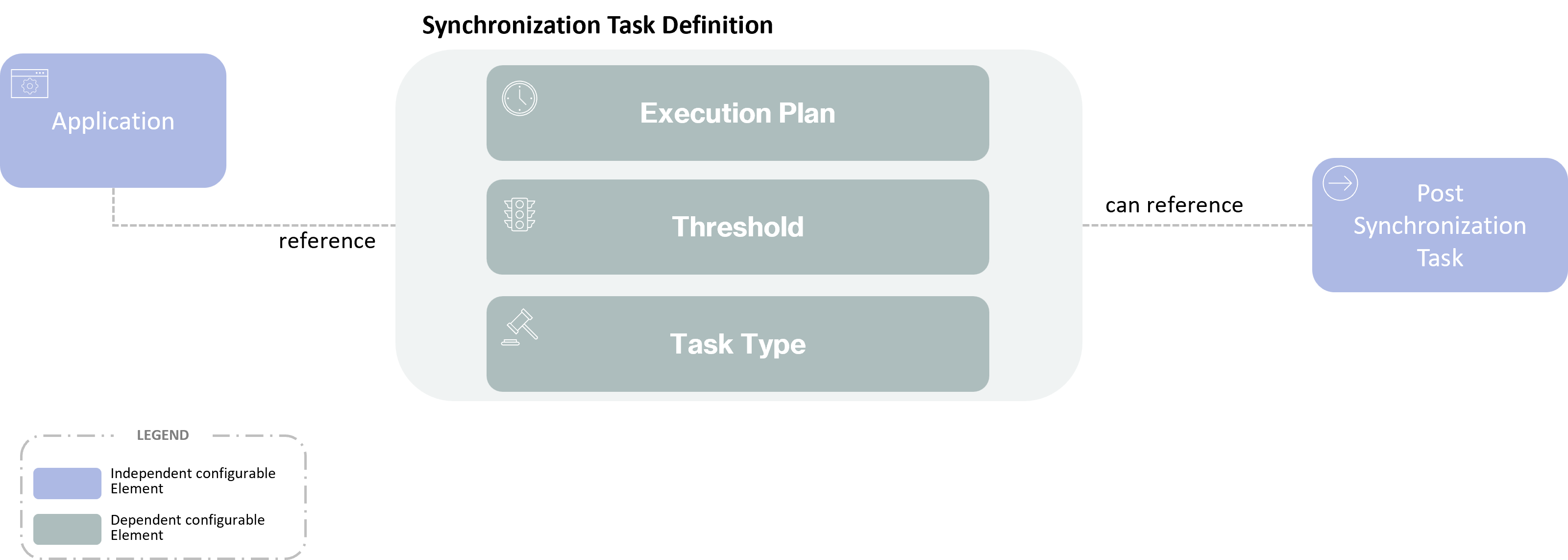
Synchronization Task Definition
Synchronization Task Definition configures the settings used to launch inbound synchronization tasks, namely by specifying the desired type of synchronization and the target Application id.
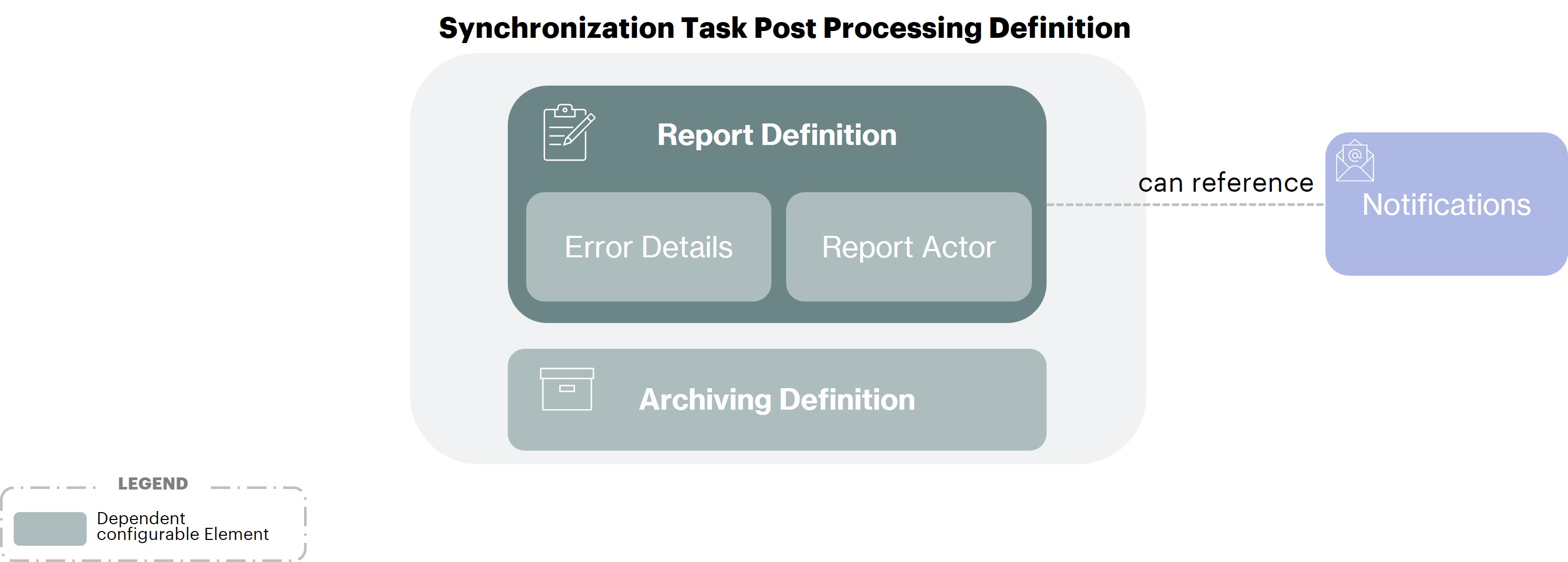
Synchronization Task Post Processing
Synchronization Task Post Processing Definition inbound only: defines a post processing configuration, which is composed of:
Synchronization Task Error Publication Definition inbound only: the settings relative to the publication of synchronization errors
Synchronization Task Report Publication Definition inbound only: the settings relative to the publication of the synchronization task report summary
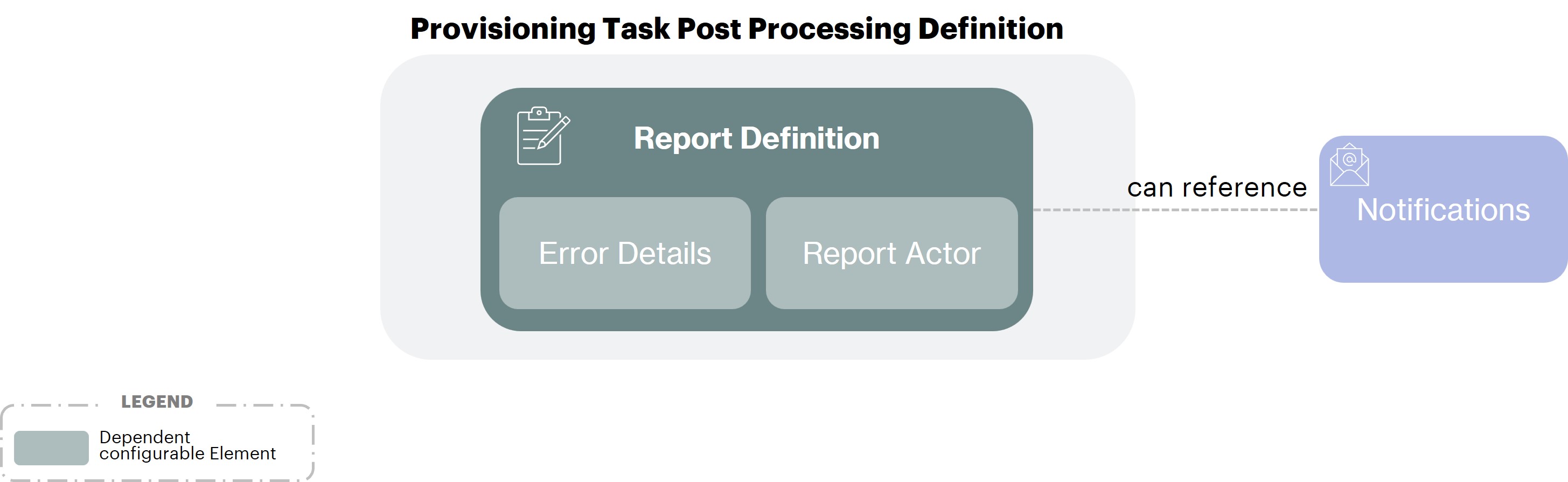
Provisioning Task Post Processing
Provisioning Task Post Processing Definition outbound only: defines a post processing configuration, which is composed of:
Provisioning Task Error Publication Definition outbound only: the settings relative to the publication of provisioning errors
Provisioning Task Report Publication Definition outbound only: the settings relative to the publication of the provisioning task report summary
Object Kind, Object Type, Shadow Kind, and Object Class
This section introduces some vocabulary that will be used later when configuring synchronization and mapping settings.
Shadow designates an object on the remote application, such as an LDAP account or a CSV file entry. Until now, for simplicity's sake, the term "account" was used in this guide to designate such an application's object, but since "account" implicitly refers to "user", it is too restrictive to be usable in the various configuration elements. Thus the generic term Shadow has been introduced. Technically speaking it also represents a local copy of the remote account state in the internal Synchronization service repository.
Object Kind designates the IDM object nature, such as Identity, Organization, etc. It is a non-configurable fixed list.
Object Type designates the IDM object type, such as "employee", "partner", etc. It is configurable.
Shadow Kind designates the application object nature. It is a non-configurable fixed list:
ACCOUNT: a user account in the application, mapped to an IdentityORGANIZATION: mapped to an IDM OrganizationRESOURCE: mapped to an IDM ResourceROLE: mapped to an IDM RoleROLE_PUBLICATION: mapped to an IDM Role PublicationENTITLEMENT: generic representation of a privilege, access right, group of the application. Not mapped to an object. They are associated with accounts on the application (not exploited yet)
Object Class designates the application object's primary native class, e.g. "inetOrgPerson" for an LDAP account. It is therefore a "technical" type, understandable by the remote application. It is presented to Synchronization service by the Connector. The Object Class can also be "virtual", namely for the CSV Connector case, where the Object Class value is fixed to __ACCOUNT__ (double underscores).
An Object Class is thus what the remote application understands. When the Synchronization service reads an object it knows its Object Class. If Synchronization service creates an object it has to define a target Object Class. The Object Class thus defines how the application object looks like. However Synchronization service does not know what to do with a specific Object Class, e.g. an LDAP inetOrgPerson. This Object Class usually defines an account, but the details can vary from deployment to deployment. Therefore Synchronization service cannot provide any fixed association between an Object Class and its usage. Synchronization service thus has to sort out the Object Class to a Shadow Kind and Object Type as specified above. While Synchronization service does not know how to handle objects of Object Class inetOrgPerson, it knows quite well what to do with objects of kind "ACCOUNT" and of type "employee".
Therefore Synchronization service maps Object Classes to (Kind, Type) tuples.
On the outbound side (Synchronization service → Connector), the mapping from (Kind, Type) to Object Class is unambiguous, straightforward. The outbound mapping is configured in the Schema Mapping Definition.
On the inbound side (Connector → Synchronization service), Object Classes are mapped to the (Kind, Type) tuple.This mapping is not very reliable and straightforward because all Synchronization service really knows about the object is its Object Class and attributes, as returned by the Connector. Therefore some kind of "guesswork" is needed to correctly sort out the object. Hence the Object Type Resolution Definition. The inbound mapping is defined in the Synchronization Definition.